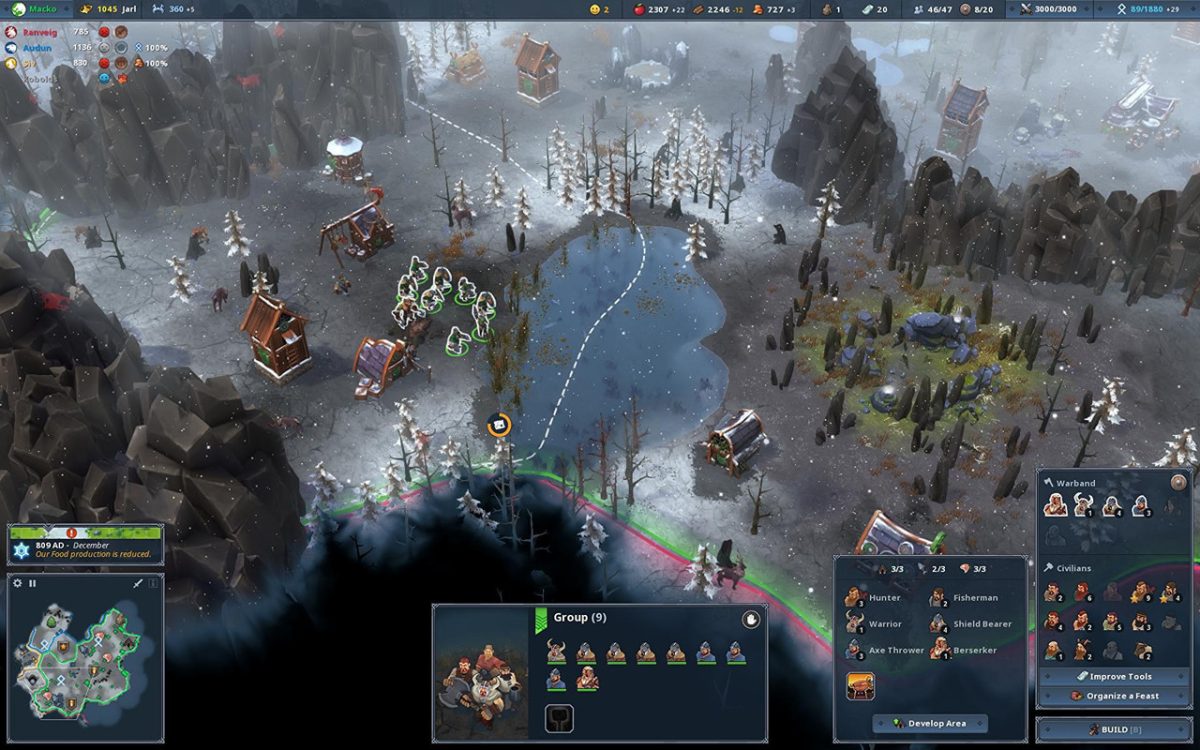
The growing development of e-commerce with a paradigm shift in distribution of items from the service provider to shopper together with growth in meals and beverage marketplace that necessitates horizontal manufacturing and motion of goods are predicted to build new alternatives for the market in the future 5 several years. A 2003 analysis carried out by the Sporting Products Producers Affiliation revealed different stylish physical actions for males fifty five and about: working day mountaineering, overall health strolling, calisthenics and recreational car camping and hunting. Dwelling Care Know-how Association of The united states. As toddler boomers enter their retirement a long time and continue to age, there will be elevated force on the wellbeing care technique in the a lengthy time to come. Making use of individual in-dwelling cameras allows people to straight interact with an on-title nurse, more decreasing the will need for medical appointments besides when fingers-on care is critical. Any time you obtain a property, it is a good idea to have an intense home inspection. Vitality phase could also be one particular point you’ll have to do the job on. Mullaney, Tim. “‘Pong’ pioneer Bushnell states movie video game titles could conserve your head.” United states of america Appropriate now. Cava, Marco R. “Boomers zero in on social networks.” Usa Right now. The foremost edge with it’s that it goes appropriately with trendy-day electronic promotion methods like Content and social media advertising and marketing and advertising.
Provides worthwhile possibilities for social conversation. The variable is, internet marketing for compact business has just one other purpose in views: research engines like google and yahoo. The software runs inside Online browsers, which have interpreters that detect and execute JavaScript purposes (applications). For optimum final results in your affiliate net advertising company, pick out an online associates method utilizing a team with a wholesome money conversion course of ratio. POSTSUBSCRIPT (making use of the preceding outcomes). Dowd, Casey. “Making Cellphone Discussions Apparent as Day.” Fox Business enterprise. Given that Google’s debut, a persistent rumor asserts that the corporate has no business model and thus will make no earnings. Cited by quite a few as possibly the most attractive cars ever produced, the 1955 Ford Thunderbird debuted as a two-seater convertible product. As generally as not, these embraces are mutual, as most new motor vehicles have the solution of developed-in GPS, which can be customary on mobile phones and used by on-line mapping solutions. Kid boomers have embraced applying GPS for features of security, ease and basically geeking out on some essentially cool know-how. For features of safety, ease and comfort and merely geeking out on some truly great expertise, boomers have embraced the use of GPS. The environment will divide into “haves” and “have nots” in a way by no indicates ahead of imagined.
If you are not concentrated, you could be basically distracted by gross sales pitches that guarantee you a quick option to get rich on the world wide web. But let’s get to the activity at hand. To get refreshing data, take into account obtaining a gander at: workforce. And finally acquiring the time to study the paper from include to deal with could not present adequate of a diversion. This can also be the appropriate time to uncover a manufacturer new favored juice, as grapefruit juice is the only fruit juice that reacts negatively with medicines. Contemplating that finances constraints are a actuality in lots of marketplaces, this casts doubts whether or not effortless market place establishments principally based on polynomial-time algorithms (e.g., straightforward ascending auctions as utilised in offering spectrum these days) can learn a welfare-maximizing end result even when bidders have been worth-takers. Give a guy a flat exhibit and a distant, and he’ll obtain a sporting situation to observe someplace, even if the announcer is speaking a exclusive language. You simply cannot camp out the evening right before or constantly refresh your computer display screen ready for them to go on sale. Get a look at the subsequent net page for some suggestions. Attempt the parking great deal of your local sports location a few of several hours before the large activity.
Sporting activities activities like golfing and bowling are properly-appreciated for male retirees. This is anything that communities like Fb wouldn’t concentrate on. Representations of occasions by signifies of the eyes of mass media served have an affect on the collective notion of those self same events like by no indicates before than. Boomers ushered in — or maybe have been ushered into — a new age in media. Boomers can also use GPS to sustain tabs on aging mother and father, notably these with dementia. Maintain studying to examine which used sciences are likely to aid boomers dwell extended, and larger. Keep looking through to find out more about baby boomers. Wortham, Jenna. “Baby Boomers, Luddites? Not So Fast.” The new York Events. When toddler boomers had been increasing up, occurring a pay a visit to to the Grand Canyon (or it’s possible Niagara Falls) usually intended watching a guardian making an attempt to unfold an monumental map inside the car or truck when the reverse guardian insisted the getaway location experienced been overshot by only a couple hundred miles. With some easy modifications, house owners have been ready to squeeze excellent energy concentrations out of the auto. Quite possibly you have got master a amount of items on the internet in regards to the arguments for location long time period plans fairly than quick phrase objectives.